-
AWS DeepRacerで機械学習について学んでみた
- 2025年5月1日
- AWS
- 機械学習

はじめに
知識がない初心者でも機械学習について実践的に学ぶことができるツールとして「AWS DeepRacer」が紹介されている記事を見かけたので、試してみることにしました。
AWS DeepRacerとは

https://aws.amazon.com/jp/deepracer/?nc=sn&loc=1
概要
- AWSが提供する強化学習を学ぶためのサービス
- 強化学習により駆動する 1/18 スケールの完全自走型レーシングカーをシミュレーター上で学習させ、レースサーキットを走らせることができる
- 実機も購入可能($399)で、学習したモデルを実際の車両にデプロイして走らせることも可能

強化学習とは
- 人工知能自身が試行錯誤しながら最適な手順を見つける学習方法
- AWS DeepRacerでは、報酬関数で行動の結果に対して報酬の数値を設定し、「報酬」を最大化するような行動を学習する
- 時間の経過とともにどのアクションが最良の報酬につながるかを特定できるようになる
料金
2025/01/09 時点の情報
- トレーニングまたは評価:3.50 USD/時間
- モデルストレージ:0.023 USD/GB/月
参考:https://aws.amazon.com/jp/deepracer/pricing/
無料利用枠
AWS DeepRacer に初めて触れるお客様には、モデルのトレーニングや評価を行うための 10 時間の無料時間枠と 5 GB の無料ストレージを提供しています (利用開始から 1 か月間)。これだけあれば、最初のタイムトライアルモデルのトレーニング、評価、チューニングを行って、AWS DeepRacer リーグに参加させるのに十分でしょう。この無料利用枠は、サービスの初回利用時から 30 日間有効です。
モデルのトレーニング・評価が10時間までは無料でできるので、デフォルトの学習時間(60分)だと9回までは無料で体験できます。(評価は1回5分程度)
AWS DeepRacer の始め方
AWSマネジメントコンソールにログイン
- マネジメントコンソールにログインし、サービス検索欄で「DeepRacer」と検索
- 「モデルを作成する」を選択
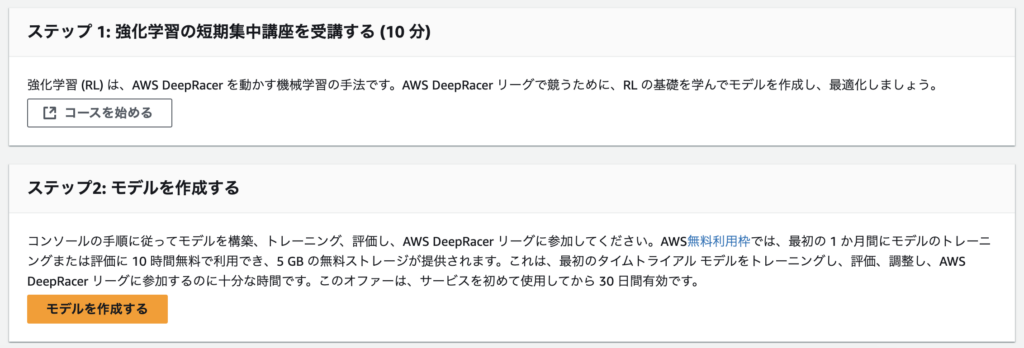
講座を受講し、モデルを作成
ステップ1の「コースを始める」から強化学習の基礎を簡単に学ぶことができます。
講座を受講し終えたら、ステップ2の「モデルを作成する」に進みます。
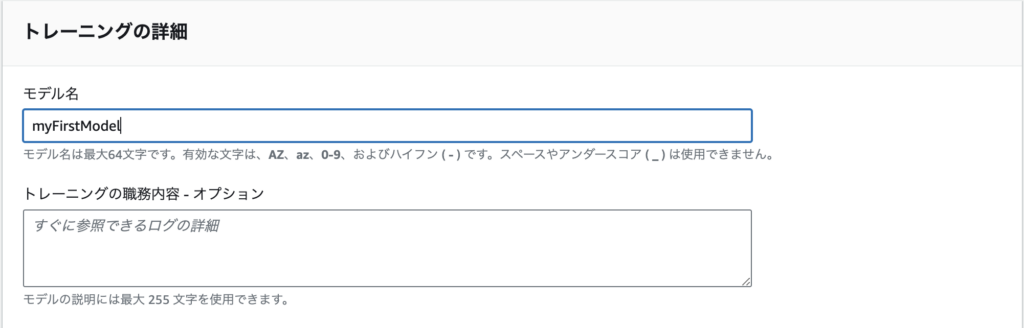
Modelの名前を設定
myFirstModelとします。
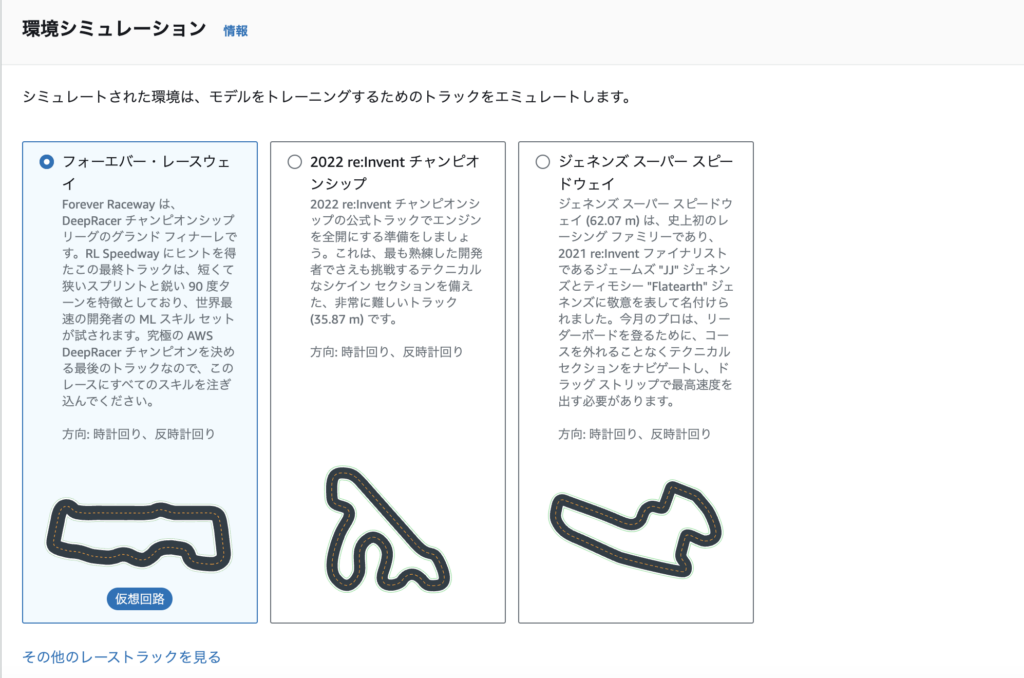
環境を選択
走行するトラックを選択します。
今回は一番シンプルなトラックを選択しました。
レースタイプを選択
今回はデフォルトのタイムトライアルを選択します。
トレーニングアルゴリズムとハイパーパラメータを選択
PPOとSACのどちらかを選択します。今回はPPOを選択しました。
- PPO:シンプルで安定した学習が特徴
- SAC:パラメータ調整の自由度が高く、経験者向け
ハイパーパラメータは初期値のままで次に進みます。
- 各パラメータについてChatGPT・Claudeに聞いてみた結果
- バッチサイズ:
- 初期値では64を設定
- 1回の学習で使用するデータ量
- 小さすぎると学習が不安定、大きすぎると学習が遅くなる
- エポック数:
- 初期値では10を設定
- モデルが同じデータを使用して何度学習するかを決める
- 1回の走行 = スタートしてから、ゴール/コースアウト/制限時間までの1試行
- 試行回数を増やすと、より多くの状況での経験を得られるが、トレーニング時間が長くなる
- 学習率:
- 初期値では0.0003を設定
- モデルの学習速度を制御
- 大きすぎると安定して走れていた動きが突然不安定になる可能性あり
- 小さすぎると同じような動きを何度も繰り返し学習が遅くなる
- エントロピー:
- 初期値では0.01を設定
- 探索(新しい行動の試行)の度合い
- 大きいほどランダムな行動が増える
- 割引率:
- 初期値では0.99を設定
- 将来の報酬をどれだけ重視するか
- 0.99は長期的な戦略の学習に適した値
- 1に近いほど将来の報酬を重視する
- 損失タイプ:
- 初期値ではフーバーを設定
- どのように学習の評価を行うかを決める設定
- フーバーは外れ値の影響を軽減しつつ、一般的なデータから効果的に学習できる
- 各ポリシー更新反復間の経験エピソードの数
- 初期値では20を設定
- どれだけのデータを使って1回の学習(ポリシー更新)を行うか設定できる
パラメータについて参考になりそうな記事:
https://qiita.com/dnp-yonezawa/items/02f6d04f71a13868b32d#ハイパーパラメータの考察
- バッチサイズ:
アクションスペースを選択
アクションスペースとは、レーシングカーが取り得る行動パターンを決定するもので、「ステアリング (ハンドル) の角度」と「速度」の組み合わせになります。
今回はより高度なチューニングが可能な「連続アクションスペース」を選択します。
アクション空間を定義
初期値のまま次に進みます。
車両を選択
現在選択できる車両は1台のみ。(昔はいろいろ種類があった模様)
報酬関数を設定し、モデルを作成
「報酬関数の例」からサンプルコードを見ることができます。
それぞれ、どのような目的のコードか解説もついているのでコードが読めない初心者でもモデル作成ができそうです。
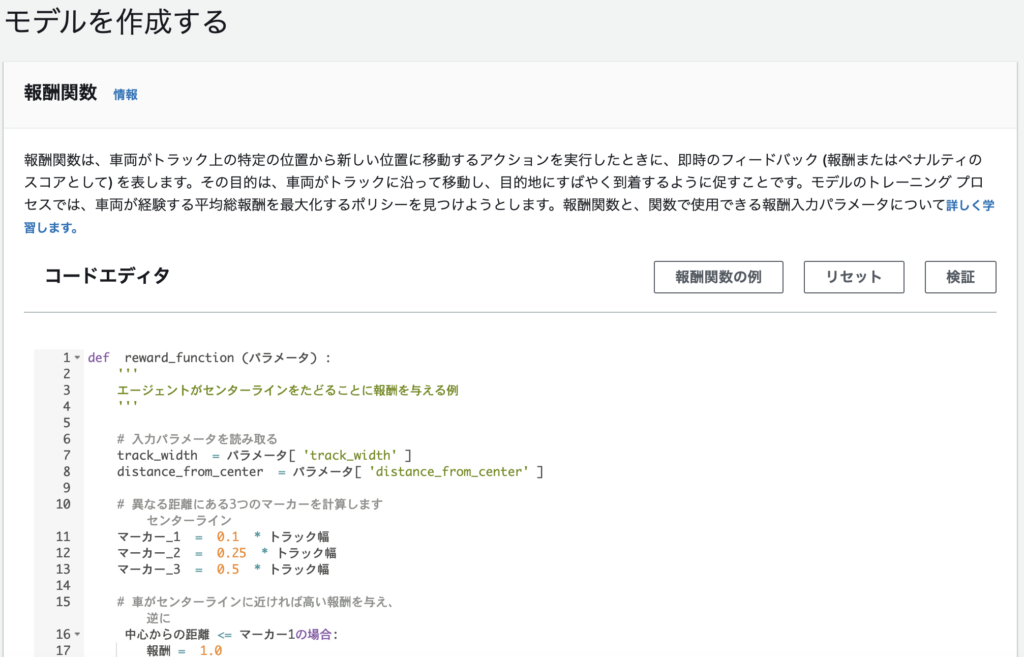
報酬関数の一例:
この例では、エージェントが中心線からどれだけ離れているかを判断し、トラックの中心に近い場合はより高い報酬を与えます。これにより、エージェントが中心線に厳密に従うように動機付けられます。
def reward_function(params):
'''
エージェントがセンターラインを通ることで報酬を与える例
'''
# 入力パラメータを読み取る
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# センターラインからの距離が異なる3つのマーカーを計算する
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# 車がセンターラインに近ければ高い報酬を与え、逆に近ければ低い報酬を与える
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # クラッシュした可能性が高い/コースアウトに近い
return float(reward)
参考:
AWS DeepRacer 報酬関数の入力パラメータ – AWS DeepRacer
停止条件
学習時間の設定をします。
初期値60分を設定しました。(無料枠内で楽しむのであればこれくらいの設定が良さそうです)
トレーニング開始!
モデルを作成し終えるとトレーニングが開始されます。
モデルの設定の「停止条件」で入力した時間の間、学習が実行されます。
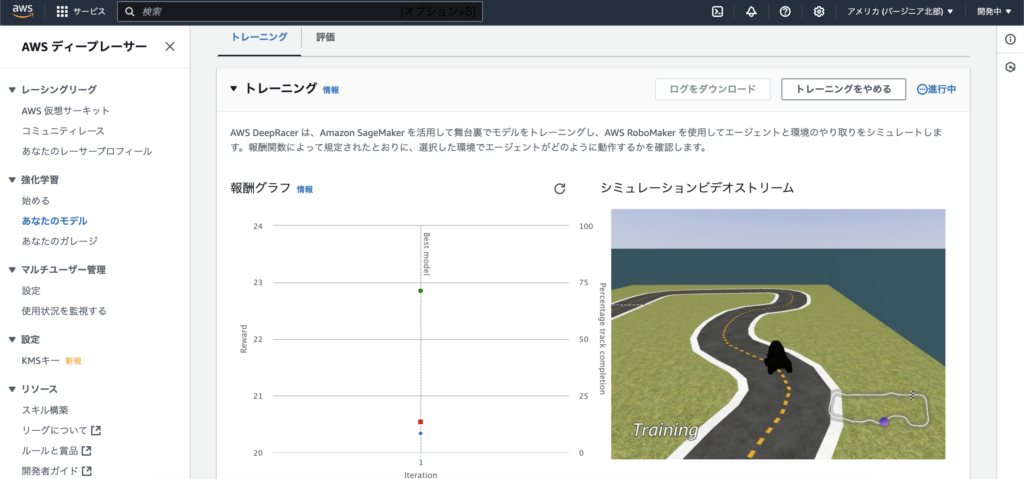
ビデオストリーミングで実際に学習している様子を見学することもできます。
コースアウトを繰り返しながら学習している模様 🚕
左側には「Reward graph」と3本のグラフ表示されています。
それぞれ以下のグラフ:
- 緑:スタートからストップまでの間(エピソード)に得た平均報酬
- 赤:評価期間中の平均完走率。
- 青:トレーニング期間中の平均完走率
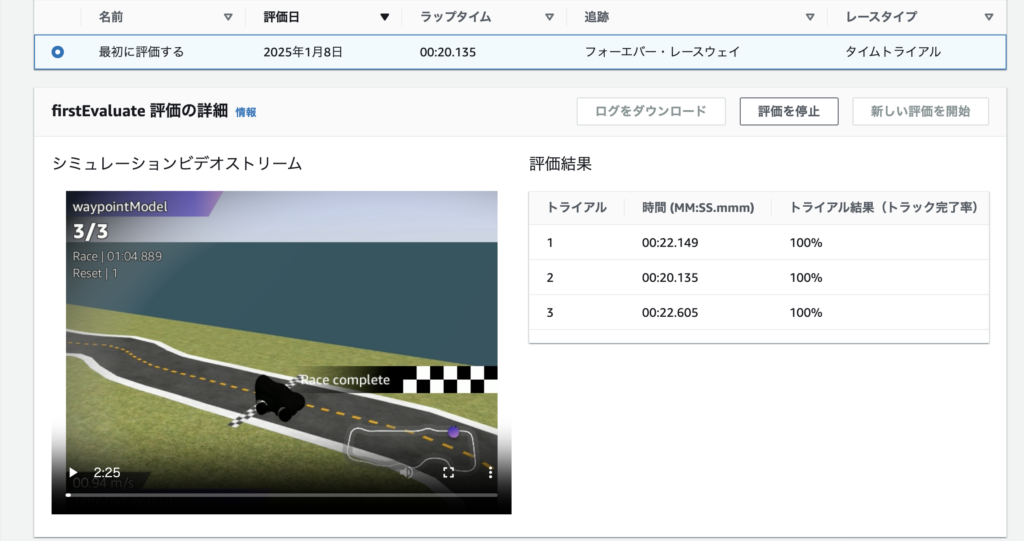
トレーニング終了後、評価を実施
評価は、トレーニングしたモデルがどの程度効果的にタスクを達成できるかをテストするプロセスです。
具体的には、トレーニングされた車両が指定されたコース上で走行し、「1周にかかったタイム」「コースアウト回数」などのパフォーマンスが測定されます。(指定した回数測定されます)
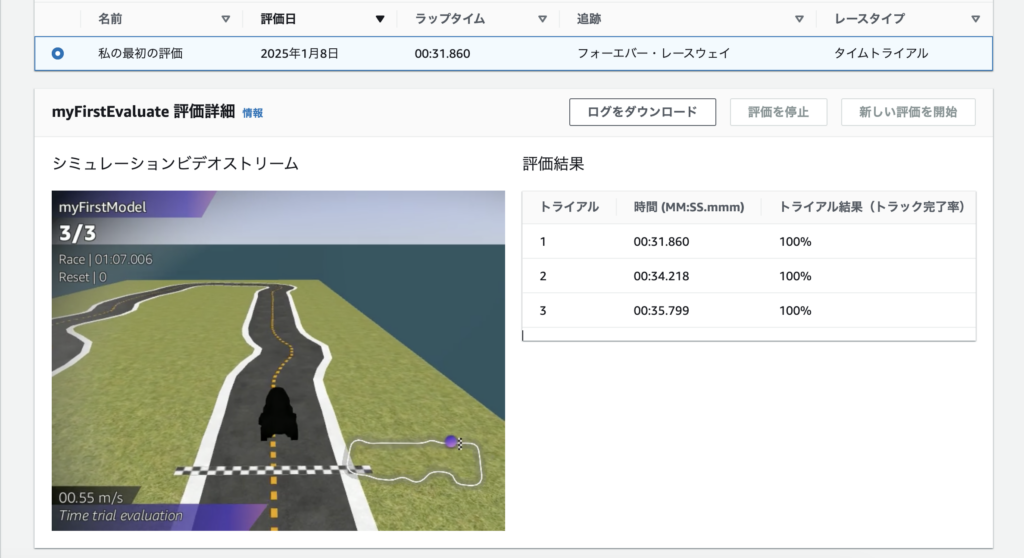
走行シミュレーションの動画を見ることもできます。
デフォルトの設定では速度は出ないものの、3回ともに完走できているので達成感を味わえます。
もう少しスピードが出せるモデルを作成してみる
以下の記事を参考に、もう少しスピードが出せるモデルを作成してみます。
AWS DeepRacerを強化する 報酬関数実装パターンあれこれ | DevelopersIO
スピード重視型モデル(大失敗)
Action space:[ 最小速度 : 最大速度 ] m/sの値を、デフォルト値 [ 0.5 : 1 ] m/s から [ 1 : 4 ] m/s に変更します。
上記の変更の上、報酬関数にて現在のスピード(m/s)を取得して、スピードが速い程高い報酬を与えます。
スピードが速くてもコースアウトしてしまうと意味がないので、コースアウトした場合は最小報酬(1e-3)を与えます。
※ 報酬が完全にゼロだとエージェントが「学ぶべき情報がない」と解釈してしまい、トレーニングが進まなくなるリスクがあるため最小値として 1e-3 を使用しているようです。
def reward_function(params):
# 全てのタイヤがトラック上にあるか否か(コースアウト判定)とスピード(m/s)をparamsから取得
all_wheels_on_track = params['all_wheels_on_track']
speed = params['speed']
# 高速と低速を判別する閾値を定義(行動パターンの設定によって変動する)
SPEED_THRESHOLD = 3.0
if not all_wheels_on_track:
# コースアウト
reward = 1e-3
elif speed < SPEED_THRESHOLD:
# 低速走行の為、報酬は少なめ
reward = 0.5
else:
# 高速走行の為、報酬は多め
reward = 1.0
return reward
評価結果:
トレーニング終了後の「Reward graph」を確認すると、1周も完走できていないことが分かります。(赤線)
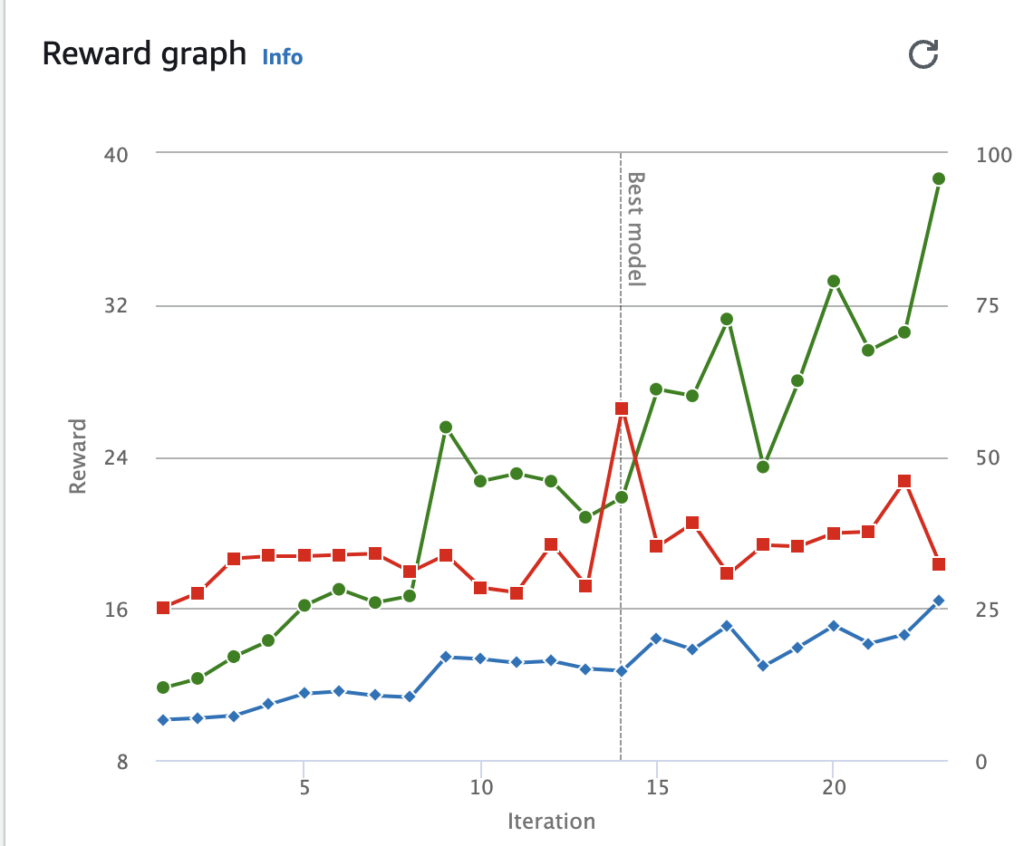
実際に学習している様子をストリーミングで確認すると、速度に対して報酬を与えているせいで爆走しすぎてカーブでのコースアウトやスピンが多く、欲張るのは良くないことを痛感しました。
このモデルを完走させるには長時間のトレーニングが必要そうなので、無料枠内で遊ぶには適していないと判断しました。
waypoint使用モデル
DeepRacerで用意されているコースにはwaypoint(コース上に配置された次に向かうべき地点の指標)が設定されています。
車体が次に向かうべきwaypointに向いた状態で走行できるように、現在の車体の向きと直近のwaypointを繋いだ方向の差分を計算し、 差分が大きい場合はペナルティを与えるよう変更を加えます。
Action space:[ 最小速度 : 最大速度 ] m/sの値を、
デフォルト値 [ 0.5 : 1 ] m/s から [ 0.5 : 2 ] m/sに変更しました。(欲張りすぎない最大速度に!)
import math
def reward_function(params):
# トラック上のwaypointと直近のwaypoint、およびコース上の基準軸に対する車体の向きをparamsから取得
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
# 規定の報酬を設定する
reward = 1.0
# 現在の位置から最も近い次のwaypointと前のwaypointを取得する
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
# 前のwaypointから次のwaypointに向かう角度(radian)を計算する
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0])
# degreeに変換
track_direction = math.degrees(track_direction)
# コース上の基準軸に対する車体の向きと直近のwaypointを繋ぐ向きの差分を取る
direction_diff = abs(track_direction - heading)
# 算出した方向の差分から車体の向きが大きくズレている場合にペナルティを与える
# 閾値の設定はコースの種類によって調整が必要
DIRECTION_THRESHOLD = 10.0
if direction_diff > DIRECTION_THRESHOLD:
reward *= 0.5
return reward
評価結果:
デフォルト値でトレーニングしたモデルでは評価結果のラップタイムが 00:31.860 だったので、おおよそ10秒タイムが縮まりました。(大満足!)
コースアウト回数もデフォルトのモデルでは3回のうち計3回コースアウトしていたが、今回のモデルでは最大速度を上げたのにも関わらず2回に収まりました。
まとめ
- DeepRacerは強化学習を実践的に学べる優れたプラットフォーム
- 視覚的なフィードバックにより初心者にも学習過程が理解しやすい
- 無料枠内でもそれなりに遊べる
- 初心者でもChatGPTと相談しながら報酬関数を作成すれば色々できそう
- 複雑なコースも用意されているので上級者はそういったコースでタイムアタックするのも良さそう
さいごに
ソリューションウェアでは、さまざまな分野の案件を幅広く持ち合わせておりスキルアップには最適の環境です。
自身のスキル向上に悩んでいる方、エンジニアとしてもう一皮むけたいと考えている方、私たちと一緒に働きませんか?
「まずはカジュアルにお話だけ」というのも可能ですので気になる方は応募フォームよりお申込みください。
この記事を書いた人 : ブログチーム
AWS bluebird css CSV docker docker compose electron ES6 es2015 Git Heroku ITコンサルティング JavaScript justinmind less MongoDB Node.js php PostgreSQL Private Space Promise React react-router reactjs Salesforce scss Selenium Builder selenium IDE Selenium WebDriver stylus TypeScript VirtualBox VisualStudioCode vue vuejs webpack システム開発プロジェクト セキュリティ ワイヤーフレーム 上流工程 卒FIT 帳票 要件定義 設計 電力小売業界